
Hardware Management in Distributed Systems
A conveyed framework comprises of various CPUs, there are a few distinct ways the equipment can be coordinated, particularly as far as how they have interconnected and the way that they impart. In this segment, we will talk about the disseminated framework equipment, particularly, how the machines are associated together.
Different order plans for numerous CPU PC frameworks have been proposed throughout the long term, yet the most well-known scientific categorization is Flynn's (1972) grouping scientific classification.
Flynn referenced two attributes that are fundamental: the number of guidance streams and the number of information streams.
SISD: A PC with a solitary guidance stream and a solitary information stream is called SISD. All customary uniprocessor PCs (i.e., those having just a single CPU) fall in this classification, from PCs to huge centralized servers.
SIMD: single guidance stream, various information streams. This type alludes to cluster processors with one guidance unit that gets guidance and afterward orders numerous information units to complete it equal, each with its own information. These machines are valuable for calculations that recurrent similar estimations on many arrangements of information, for instance, including every one of the components of 64 autonomous vectors. A few supercomputers are SIMD.
MISD: different guidance streams, single information stream. No realized PCs fit this model.
MIMD: which basically implies a gathering of free PCs, each with its own program counter, program, and information. All circulated frameworks are MIMD
All MIMD PCs are into two gatherings:
Those that have shared memory, are typically called Multiprocessors.
Those that don't have shared memory are once in a while called Multicomputer. The fundamental contrast is this:
• In a multiprocessor (All the machines share a similar memory.), there is a solitary virtual location space that is shared by all CPUs. In the event that any CPU composes, for instance, the worth 44 to address 1000, some other CPU thusly perusing from its location 1000 will get the worth 41.
• In any case, in a Multicomputer, each machine has its own confidential memory. In the event that one CPU composes the worth 44 to address 1000 when another CPU peruses address 1000 it will get anything esteem was there previously. The compose of 44 doesn't influence its memory by any stretch of the imagination. A typical illustration of a multicomputer is an assortment of PCs associated by an organization.
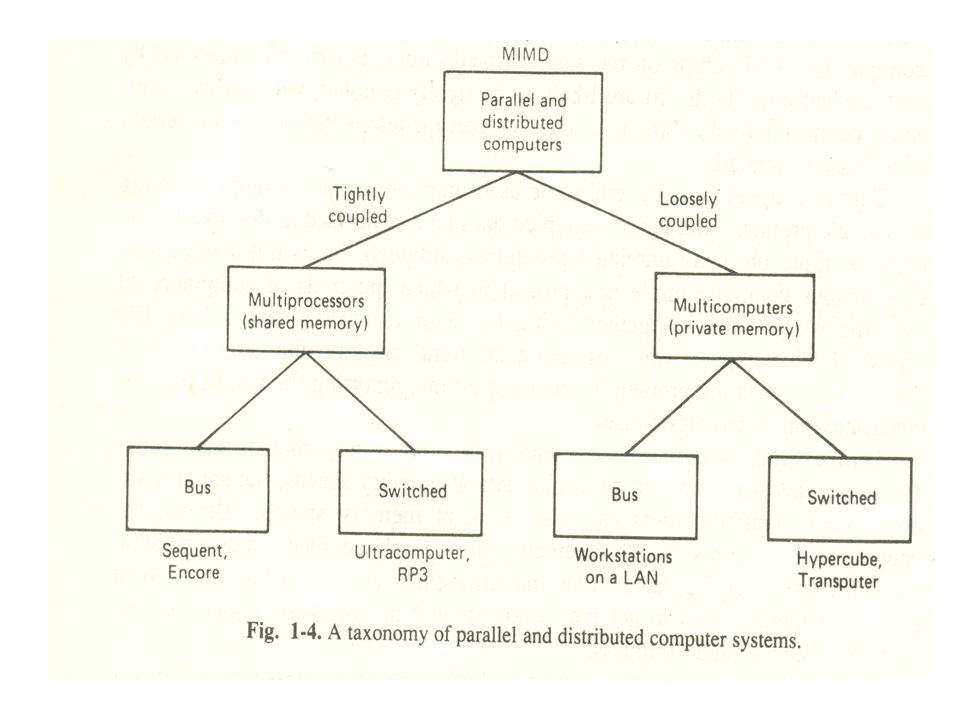
Every one of these classifications can be additionally isolated in light of the engineering of the interconnection organization. In Fig.1
we portray these two classifications as Bus and Switched.
Transport: There is a solitary organization, backplane, transport, link, or another medium that interfaces every one of the machines. Digital TV utilizes a plan like this: the link organization runs a wire down the road, and every one of the endorsers have taps rushing to it from their TVs.
Exchanged: Switched frameworks don't have a solitary spine like digital TV. All things considered, there are individual wires from one machine to another, with a wide range of wiring designs being used. Messages move along the wires, with an unequivocal exchanging choice made at each move toward course the message alongside one of the active wires. The overall public phone framework is coordinated along these lines.
One more aspect to our scientific categorization is that in certain frameworks the machines are firmly coupled and in others, they are approximately coupled.
In a firmly coupled framework, the postpone experienced when a message is sent starting with one PC then onto the next is short, and the information rate is high; that is, the quantity of pieces each subsequent that can be moved is enormous. two CPU chips on a similar printed circuit board and associated by wires fixed onto the board are probably going to be firmly coupled
In an approximately coupled framework, the inverse is valid: the intermachine message delay is huge and the information rate is low. two PCs associated by a 2400 cycle/sec modem via phone framework are sure to be inexactly coupled.
Firmly coupled frameworks will generally be involved more as equal frameworks (figuring out on a solitary issue) and inexactly coupled ones will generally be utilized as dispersed frameworks (dealing with on numerous irrelevant issues), albeit this isn't correct 100% of the time.
In general, multiprocessors will quite often be more firmly coupled than multi-PCs, since they can trade information at memory speeds, yet some fibreoptic based multicomputer can likewise work at memory speeds.
In the accompanying four segments, we will check out at the four classes of Fig. 1 in more detail, to be specific transport multiprocessors, exchanged multiprocessors, transport multicomputer, and exchanged multicomputer.
Transport Based Multiprocessors
Transport based multiprocessors comprise of various CPUs generally associated with a typical transport, alongside a memory module.
A basic setup is to have a fast backplane or motherboard into which CPU and memory cards can be embedded.
A run of the mill transport has 32 or 64 location lines, 32 or 64 information lines, and maybe at least 32 control lines, all of which work in equal.
To peruse an expression of memory, a CPU puts the location of the word it needs on the transport address lines, then puts a sign on the proper control lines to show that it needs to peruse. The memory answers by putting the worth of the word on the information lines to permit the mentioning CPU to peruse it in. Composes work along these lines.
Exchanged Multiprocessors
To fabricate a multiprocessor with in excess of 64 processors, an alternate strategy is expected to interface the CPUs with the memory. One chance is to separate the memory into modules and interface them to the CPUs with a crossbar switch.
Every CPU and every memory has an association emerging from it, as displayed.
At each convergence is a small electronic cross point switch that can be opened and shut in equipment.
Whenever a CPU needs to get to a specific memory, the cross-point switch interfacing them is shut quickly, to permit the admittance to happen.
The upside of the crossbar switch is that numerous CPUs can be getting to memory simultaneously.
However, assuming that two CPUs attempt to get to a similar memory all the while, one of them should stand by.
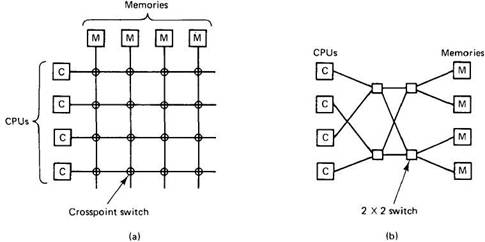
The drawback of the crossbar switch is that with n CPUs and n recollections, n2 cross-point switches are required. For enormous n, this number can be unreasonably expensive.
Subsequently, individuals have searched for, and found, elective exchanging networks that require less switches.
Another chance is to have the omega switch
This organization contains four 2x2 switches, each having two information sources and two results.
Each switch can course either contribution to one or the other result.
with legitimate settings of the switches, each CPU can get to each memory. These switches can be set in nanoseconds or less.
In the general case, with n CPUs and n recollections, the omega network requires log2n exchanging stages, each containing n/2 switches, for a sum of (n log2n)/2 switches. In spite of the fact that for enormous n this is far superior to n<sup>2</sup>.
To sum up, transport based multiprocessors:
with snoopy stores, are restricted by how much transport ability to around 64 CPUs all things considered.
To go past that requires an exchanging organization, for example, a crossbar switch, an omega exchanging organization, or something almost identical.
Enormous crossbar switches are extravagant, and huge omega networks are both costly and slow. The decision is clear: fabricating a huge, firmly coupled, shared memory multiprocessor is conceivable, however is troublesome and costly.
Transport Based Multicomputer
Then again, building a multicomputer (i.e., no common memory) is simple.
Every CPU has an immediate association with its own nearby memory.
The main issue left is the means by which the CPUs speak with one another. Obviously, some interconnection plot is required here, as well, however since it is just for CPU-to-CPU correspondence, the volume of traffic will be a few significant degrees lower than when the interconnection network is likewise utilized for CPU-to-memory traffic.
sdfsgf
It looks topologically like the transport based multiprocessor, yet since there will be substantially less traffic over it, it need not be a high velocity backplane transport.
Truth be told, it very well may be a much lower speed LAN (regularly, 10-100 Mbps, looked at
to 300 Mbps and up for a backplane transport).
In this way Fig 4 is all the more frequently an assortment of workstations on a LAN than
an assortment of CPU cards embedded into a quick transport.

Switched Multicomputer
Our last class comprises of exchanged multicomputer.
Different interconnection networks have been proposed and constructed, however all have the property that every CPU has immediate and selective admittance to its own, confidential memory.
Figure 5 shows two famous geographies, a matrix, and a hypercube.
Lattices are straightforward and format on printed circuit sheets. They are
the most appropriate to issues that have an innate two-layered nature.
-
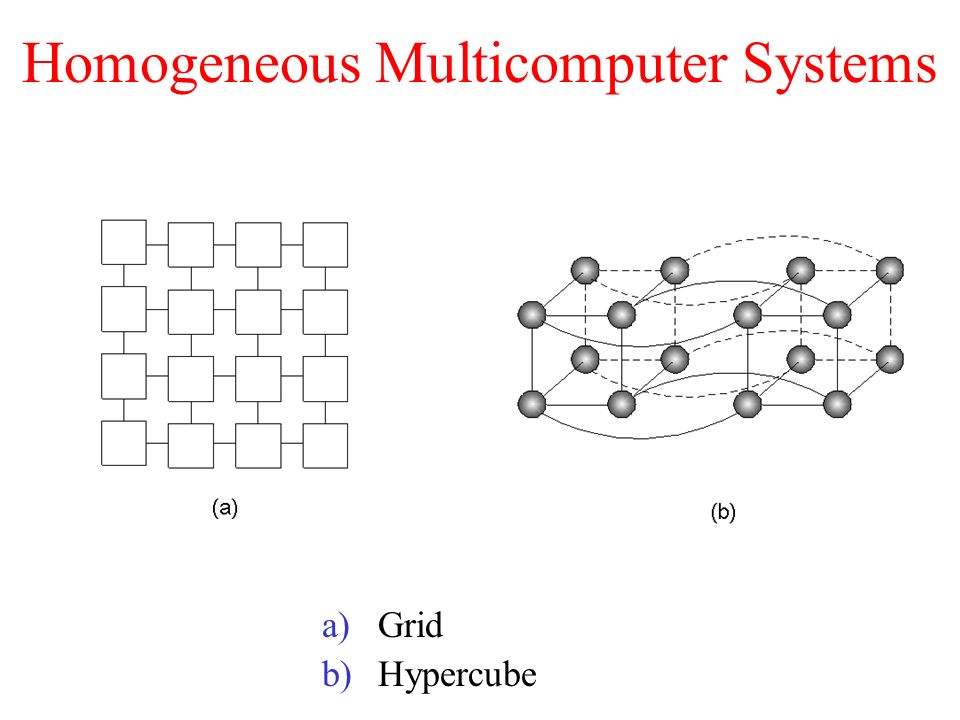
An n-dimensional cube is known as a hypercube. The four-dimensional hypercube in Figure 5(b) is a cube. It can be compared to two regular cubes with 8 vertices and 12 edges each. Every vertex contains a CPU. Two CPUs are connected by each edge. Each of the two cubes' corresponding vertices is connected.
We would add another set of two interconnected cubes to the figure, connect the matching edges in the two halves, and so forth to expand the hypercube to five dimensions.
Each CPU has an equal number of connections to other CPUs for an n-dimensional hypercube. As a result, the wiring complexity only grows logarithmically with size. Only the closest neighbours are connected, thus many communications must hop across multiple neighbours before they arrive at their final destination.
Thanks for reading, if you liked it please share it with your peers